The Dark Side of AI in Call Summarization: Privacy, Personalization
The Dark Side of Call Summarizing AIs in Mobiles
In today’s digital age, artificial intelligence (AI) is becoming increasingly pervasive, seamlessly integrating into various aspects of our lives. One such integration is the use of AI in mobile devices to summarize calls, a feature that promises convenience but comes with significant privacy and ethical concerns. Companies like Samsung (with Bixby), Apple (with Intelligence), and Jio (with Phonecall AI) have introduced this technology, touting it as a way to enhance user experience. However, the implications of these advancements go far beyond mere convenience. In this post, we will explore the dark side of call summarizing AIs, focusing on how they process data in the cloud, store it, and use it for personalization, targeted ads, and training large language models (LLMs).
1. Introduction
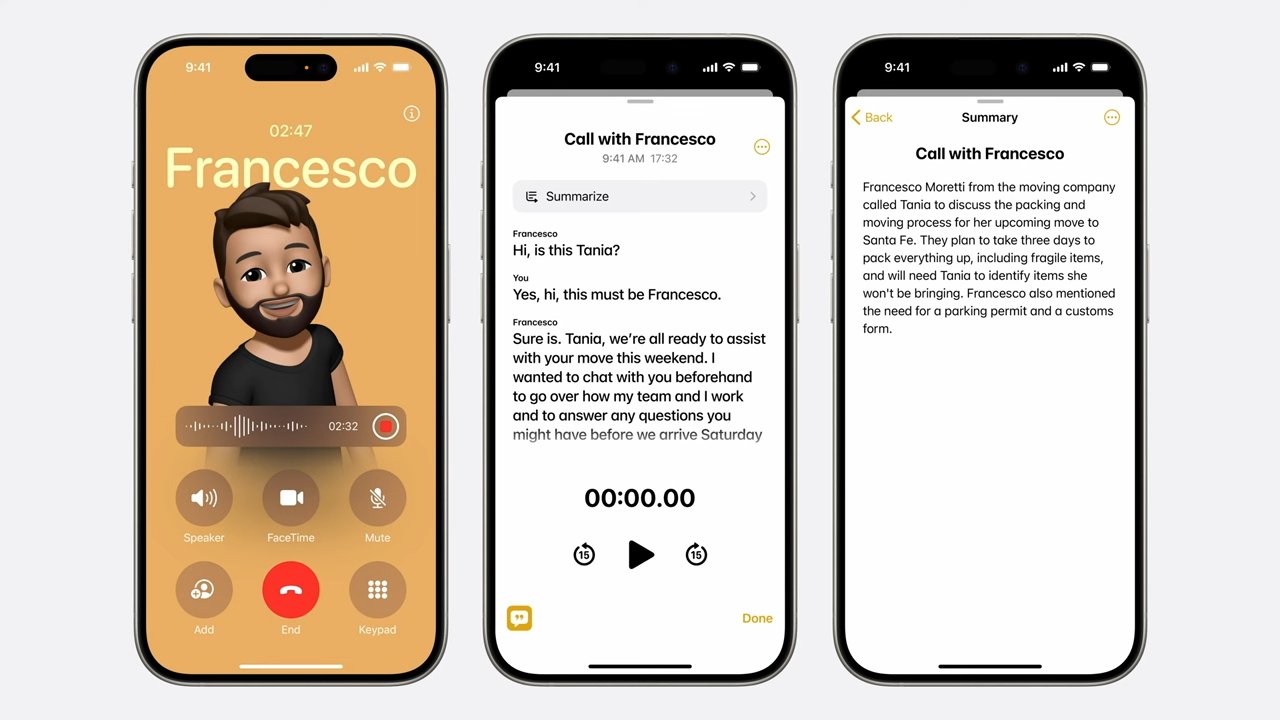
As smartphones evolve, so does the sophistication of the AI embedded within them. One of the latest trends in AI applications is call summarization—where AI listens to a call, transcribes it, and provides a concise summary. This feature is marketed as a tool to help users keep track of important conversations, freeing them from the burden of remembering every detail or manually taking notes. But while the benefits are clear, the hidden costs to privacy, data security, and user autonomy are often overlooked.
2. How Call Summarization AI Works
2.1. The Technology Behind Call Summarization
At its core, call summarization AI relies on several key technologies:
-
Automatic Speech Recognition (ASR): This is the first step in the call summarization process. ASR technology converts spoken language into text. Advanced ASR models use deep learning techniques, particularly Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs), to improve accuracy. These models are trained on vast amounts of audio data to recognize speech patterns, accents, and even background noise.
-
Natural Language Processing (NLP): Once the speech is transcribed, NLP algorithms analyze the text to identify the key points of the conversation. This involves various techniques such as Named Entity Recognition (NER), sentiment analysis, and topic modeling. NER helps in identifying important entities like names, dates, and locations, while sentiment analysis gauges the emotional tone of the conversation.
-
Summarization Algorithms: After processing the text, summarization algorithms condense the information. There are two primary types of summarization techniques: extractive and abstractive. Extractive summarization selects the most important sentences from the text, while abstractive summarization generates new sentences that convey the essence of the conversation. Abstractive summarization is more challenging but provides more concise and natural summaries.
2.2. The Role of Cloud Computing
Given the computational complexity of these processes, most call summarization AI systems rely on cloud computing. When a call is made, the audio is often uploaded to cloud servers, where the heavy lifting—speech recognition, NLP, and summarization—takes place. The summarized text is then sent back to the user’s device.
The cloud infrastructure enables these AIs to scale effectively, handle large volumes of data, and continuously improve through updates. However, this reliance on the cloud introduces significant privacy concerns, as users’ call data must be transmitted and stored on remote servers.
2.3. Real-Time vs. Post-Call Summarization
Call summarization can be performed in real-time or after the call has ended. Real-time summarization requires low-latency processing, which means that the audio data must be quickly uploaded, processed, and returned to the user. This is particularly challenging and necessitates robust cloud infrastructure and optimized algorithms.
Post-call summarization, on the other hand, can afford to be slower, allowing for more thorough analysis and summarization. However, it still involves the same privacy risks, as the call data must be stored temporarily in the cloud for processing.
3. Data Storage and Privacy Concerns
3.1. The Implications of Cloud Storage
Storing call data in the cloud is a double-edged sword. On one hand, it allows for the scalability and flexibility needed to run complex AI algorithms. On the other hand, it raises significant privacy concerns. Once call data is uploaded to the cloud, it is potentially accessible not only to the service provider but also to anyone who might gain unauthorized access to the servers.
Data stored in the cloud is subject to the policies and security measures of the service provider. Even with robust encryption, there is always a risk of data breaches, either through hacking, insider threats, or vulnerabilities in the system. Additionally, the data might be stored in multiple locations, sometimes in different countries, making it subject to various legal jurisdictions and privacy laws.
3.2. Data Retention Policies
Another critical issue is the data retention policies of companies offering call summarization services. How long is your call data stored? What guarantees do users have that their data will be deleted after a certain period? Often, these details are buried in terms of service agreements that few users read.
In some cases, companies might retain call data for extended periods to improve their AI models, potentially without explicit user consent. This long-term storage of personal conversations raises questions about user autonomy and control over personal data.
3.3. Risks of Unauthorized Access
The risk of unauthorized access to stored call data is a significant concern. This could come from external attackers, malicious insiders, or even government surveillance. For example, a breach of a cloud provider’s servers could expose millions of users’ private conversations, leading to potential identity theft, blackmail, or other malicious activities.
Furthermore, if the call data includes sensitive information—such as financial details, medical information, or personal relationships—the impact of a breach could be devastating.
4. Personalization and Targeted Ads
4.1. How Call Data is Used for Personalization
Personalization is a major selling point for many AI-driven services. By analyzing call data, companies can build detailed profiles of users, including their preferences, interests, and behaviors. For example, if a user frequently discusses travel during their calls, the AI might suggest travel-related content or services.
This level of personalization can enhance the user experience, making interactions with digital services more relevant and engaging. However, it also means that companies are constantly monitoring and analyzing users’ private conversations, potentially infringing on their privacy.
4.2. The Intersection with Targeted Advertising
The data collected from call summaries is incredibly valuable for targeted advertising. By understanding what users are talking about, companies can deliver ads that are more likely to resonate with them. For instance, if a user mentions they are planning to buy a new car, they might start seeing ads for car dealerships or automotive products.
While targeted ads can be more relevant, they also raise concerns about the extent of data collection and the lack of transparency. Users may not be fully aware that their private conversations are being mined for advertising purposes, leading to a sense of intrusion and loss of privacy.
4.3. The Ethical Dilemma
The use of personal data for targeted advertising presents a significant ethical dilemma. On one hand, it allows companies to offer services that are more aligned with users’ needs. On the other hand, it involves the commodification of personal information, where users’ private conversations are treated as a resource to be exploited for profit.
This raises questions about consent and control. Do users fully understand how their data is being used? Are they given meaningful choices about whether to opt in or out of these practices? In many cases, the answer is no, which undermines the ethical foundation of these technologies.
5. Training Large Language Models (LLMs)
5.1. The Role of Call Data in Training LLMs
Large language models like GPT-3 and GPT-4 are trained on vast amounts of text data, including transcriptions of spoken conversations. The data from call summaries can be particularly valuable for training these models, as it provides real-world examples of how people communicate, including nuances like tone, context, and intent.
By incorporating call data into their training sets, companies can improve the accuracy and sophistication of their language models, enabling them to better understand and generate human-like text. However, this practice raises significant privacy concerns, especially if the data used for training includes sensitive or personally identifiable information.
5.2. Anonymization and its Limitations
One way to mitigate privacy concerns is to anonymize the data before using it to train LLMs. Anonymization involves removing or obfuscating information that could identify individuals. However, true anonymization is difficult to achieve, especially with conversational data that may include unique patterns, voices, or contextual clues that could be traced back to specific individuals.
Moreover, even anonymized data can be vulnerable to re-identification attacks, where attackers use auxiliary information to match anonymized data with its original source. This means that even with anonymization, there is still a risk that personal conversations could be exposed or misused.
5.3. The Implications for User Trust
The use of call data for training LLMs can erode user trust, especially if users are not fully aware of how their data is being used. Transparency is crucial, but it is often lacking in the way companies communicate their data practices. Users may feel betrayed if they discover that their private conversations have been used to train AI models without their explicit consent.
This erosion of trust can have broader implications for the adoption of AI technologies. If users feel that their privacy is not being respected, they may become more hesitant to use AI-driven services, potentially stalling the progress of AI innovation.
6. Ethical and Legal Implications
6.1. Ethical Considerations in AI Development
The development and deployment of AI technologies, particularly those that handle sensitive data like call summaries, must be guided by ethical principles. This includes ensuring that users are informed about how their data is being used, giving them control over their data, and respecting their privacy.
However, the reality is often more complex. Companies are incentivized to collect and use as much data as possible to improve their AI models and deliver personalized services. This can lead to a conflict between the desire for innovation and the need to protect users’ rights.
Ethical AI development also involves considering the broader societal impacts of these technologies. For example, how might the use of call data for AI training contribute to biases in language models? Could it lead to unintended consequences, such as reinforcing stereotypes or enabling surveillance?
6.2. The Legal Landscape
The legal landscape surrounding AI and data privacy is still evolving. In many jurisdictions, existing privacy laws were not designed with AI technologies in mind, leading to gaps in regulation. For example, the General Data Protection Regulation (GDPR) in Europe provides some protections for personal data, but it is not always clear how these apply to AI-driven services like call summarization.
In the absence of comprehensive legal frameworks, companies often set their own standards, which can vary widely. This lack of consistency can lead to confusion and uncertainty for users, who may not know what protections are in place or what recourse they have if their data is misused.
6.3. The Role of Transparency and Accountability
To address these ethical and legal challenges, transparency and accountability are key. Companies must be transparent about how they collect, store, and use call data, and they must be held accountable for any misuse of that data.
This could involve clearer terms of service, regular audits of AI systems, and stronger enforcement of privacy laws. It could also involve giving users more control over their data, such as the ability to opt out of data collection or request the deletion of their data.
Ultimately, building trust with users will require companies to go beyond compliance and demonstrate a genuine commitment to ethical AI practices.
7. Conclusion
The rise of call summarizing AIs in mobile devices represents a significant technological advancement, offering users the convenience of having their conversations transcribed and summarized. However, this convenience comes with a hidden cost: the potential erosion of privacy, the commodification of personal data, and the ethical dilemmas surrounding the use of AI.
As we have explored in this post, the dark side of call summarization AI lies in the way these technologies handle, store, and use our data. From the risks of cloud storage to the ethical implications of training LLMs on personal conversations, there are numerous challenges that must be addressed.
To protect users and ensure the responsible development of AI, it is crucial that we have transparent data practices, robust legal frameworks, and a commitment to ethical AI development. Only then can we fully harness the benefits of call summarization AI without compromising our privacy and autonomy.